Machine Learning Algorithms for Beginners
Understanding machine learning algorithms is the first step in exploring the world of artificial intelligence. These algorithms serve as the backbone of systems that can learn from data and make decisions. For beginners, diving into this field can seem daunting, but starting with foundational concepts and tools makes the journey much more approachable. This article guides you through essential machine learning algorithms, offering insights into their applications and how to get started.
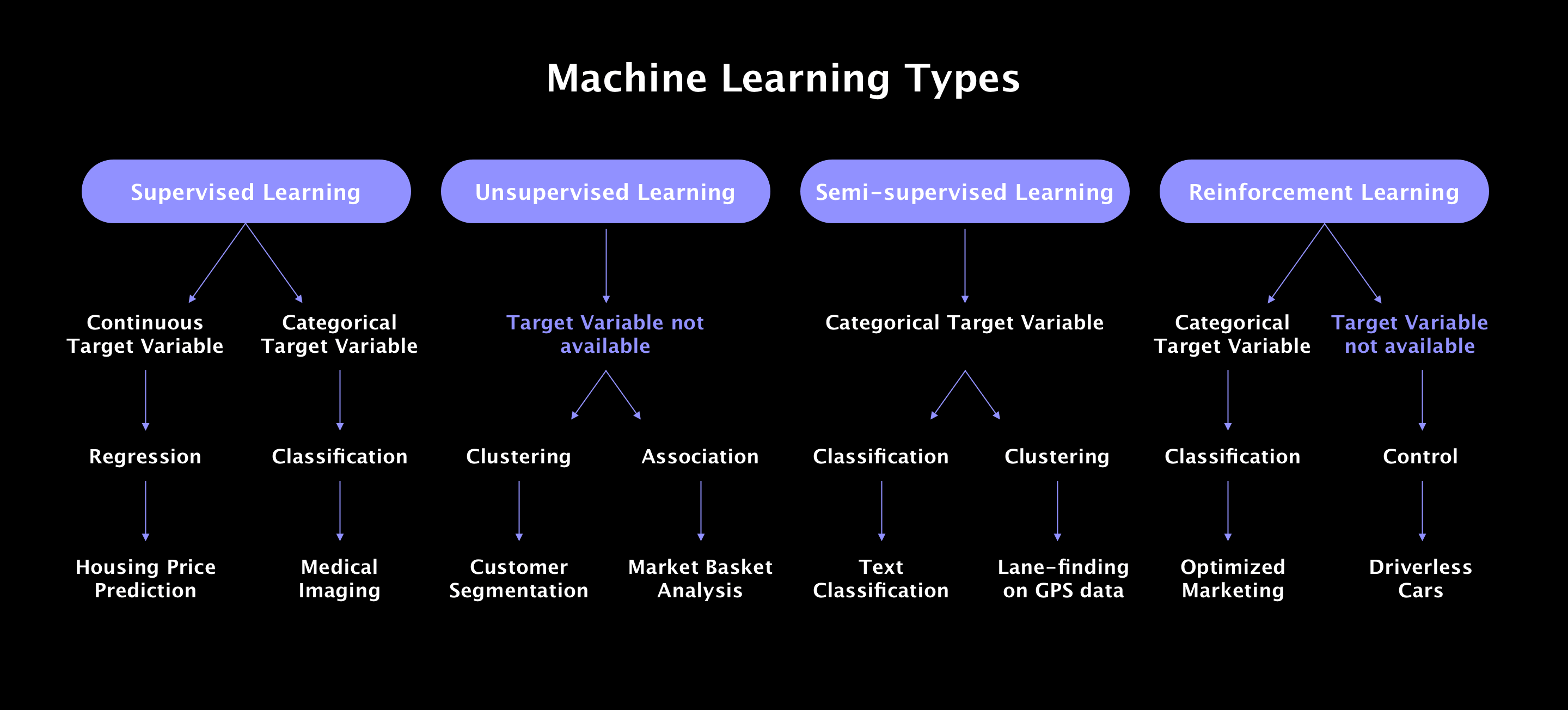
Figure: An overview of machine learning types and their algorithms.
Introduction to Machine Learning Algorithms
Machine learning relies on algorithms that can process data, identify patterns, and make predictions or decisions. There are two main categories:
- Supervised Learning: Algorithms learn from labeled data, making predictions or classifications.
- Unsupervised Learning: Algorithms analyze unlabeled data to find hidden patterns or groupings.
For beginners, starting with supervised learning is often easier because it involves clear outcomes and goals.
“Machine learning is like teaching a computer to recognize patterns, and every algorithm has a specific role in this process.”
At DUYTHIN.DIGITAL, we specialize in tools that automate workflows across platforms like Facebook, TikTok, and Google SEO—parallels that show the power of automation, much like machine learning itself.
Supervised Learning Algorithms
Supervised learning forms the foundation for many real-world applications, including recommendation systems, fraud detection, and predictive analytics.
Linear Regression
Linear regression is one of the simplest algorithms in machine learning. It predicts a continuous numerical value based on input variables, establishing a straight-line relationship between inputs (independent variables) and outputs (dependent variable). This algorithm is widely used in fields like finance and real estate.
Example:
Predicting house prices based on factors like size, location, and number of rooms.
Benefits:
- Easy to understand and implement.
- Suitable for datasets with linear relationships.

Figure: Visual representation of a linear regression model.
External Resource: Learn more about implementing linear regression in Python.
Logistic Regression
Despite its name, logistic regression is used for classification problems, not regression. It predicts the probability of an instance belonging to a specific class. Logistic regression uses the sigmoid function to ensure predictions fall between 0 and 1, making it perfect for binary classifications.
Example:
Classifying whether an email is spam or not spam.
Benefits:
- Works well for small datasets.
- Interpretable and straightforward.
Pro Tip: Use logistic regression for simple binary classification tasks before moving to more complex algorithms like decision trees or ensemble methods.
Decision Trees
Decision trees are intuitive and easy to visualize. They work by splitting data into branches based on feature values, forming a tree-like structure. Decision trees can be used for both classification and regression tasks, making them versatile for beginners.
Example:
Predicting whether a loan applicant will default based on income, age, and credit score.
Benefits:
- Easy to interpret.
- Handles both numerical and categorical data.
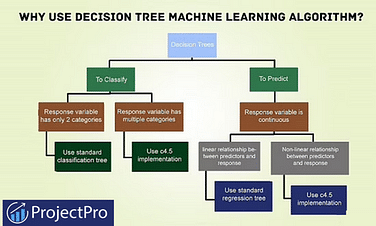
Figure: A simple decision tree structure.
External Resource: Explore how to build decision trees in Python.
Naive Bayes
Naive Bayes is a probabilistic algorithm that uses Bayes’ theorem. It assumes feature independence, making it simple but highly effective for certain tasks like text classification. Its performance is often surprising given its simplicity.
Example:
Sentiment analysis of customer reviews (positive or negative).
Benefits:
- Fast and efficient, even with large datasets.
- Works exceptionally well for text data.
Related Keyword: Text classification algorithms.
K-Nearest Neighbors (KNN)
KNN is a non-parametric algorithm that predicts the output of a data point based on its proximity to other data points in the feature space. It is highly intuitive and effective for small datasets.
Example:
Classifying images of handwritten digits based on pixel intensity.
Benefits:
- Easy to implement.
- No assumption about the underlying data distribution.
Figure: KNN identifies the closest neighbors to classify or predict outcomes.
External Resource: Discover how to implement KNN in Scikit-learn.
Unsupervised Learning Algorithms
Unsupervised learning algorithms work with unlabeled data to uncover hidden patterns or groupings, making them ideal for exploratory data analysis.
K-Means Clustering
K-Means clustering groups similar data points into predefined clusters. It’s commonly used in marketing for customer segmentation or anomaly detection in financial transactions.
Example:
Segmenting customers into groups based on purchasing behavior.
Benefits:
- Easy to understand and implement.
- Scales well with larger datasets.
Pro Tip: Visualize clusters using PCA for better insights.
In the next half of this article, we’ll explore Principal Component Analysis (PCA), ensemble methods, and practical tips to implement these algorithms effectively. Stay tuned to dive deeper into machine learning algorithms and unlock their full potential!